|
Yuheng Tu I am a first-year MSCS student at UCLA. I was an undergrad from Southeast University (SEU). I was a visiting student at UC Berkeley EECS during 24 Spring. I have the privilege of working with Prof. Sanmi Koyejo. Before this, I was fortunate to be advised by Prof. Bo Li during 24 summer and Prof. Qiao Wang at SEU. I am a CS self-learning advocate and my study notes are presented in CS-self-learning. I led SEU Flybook 2025, an open-source guide for SEU students applying to MS/PhD programs abroad. My recent research focuses on AI Measurement Science (a prerequisite for trustworthy AI), drawing on insights from statistics and psychology. My study interests lie in CS/AI, CS/Theory, and Statistics. |

|
Research |
|
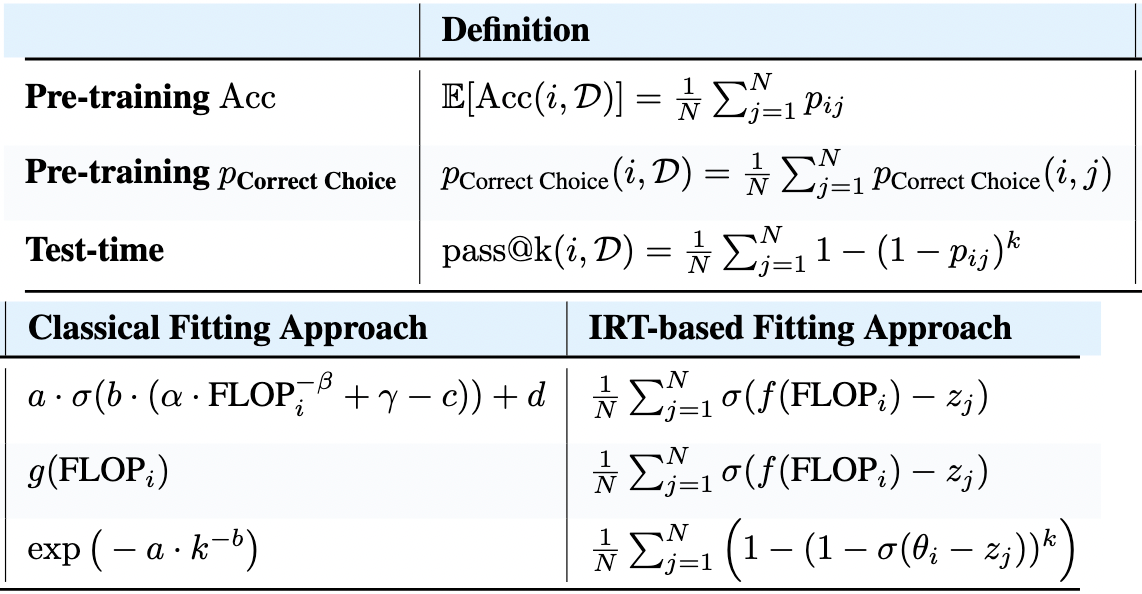
Sang Truong*, Yuheng Tu*, Rylan Schaeffer, Sanmi Koyejo Under Review PDF / Code
|
|
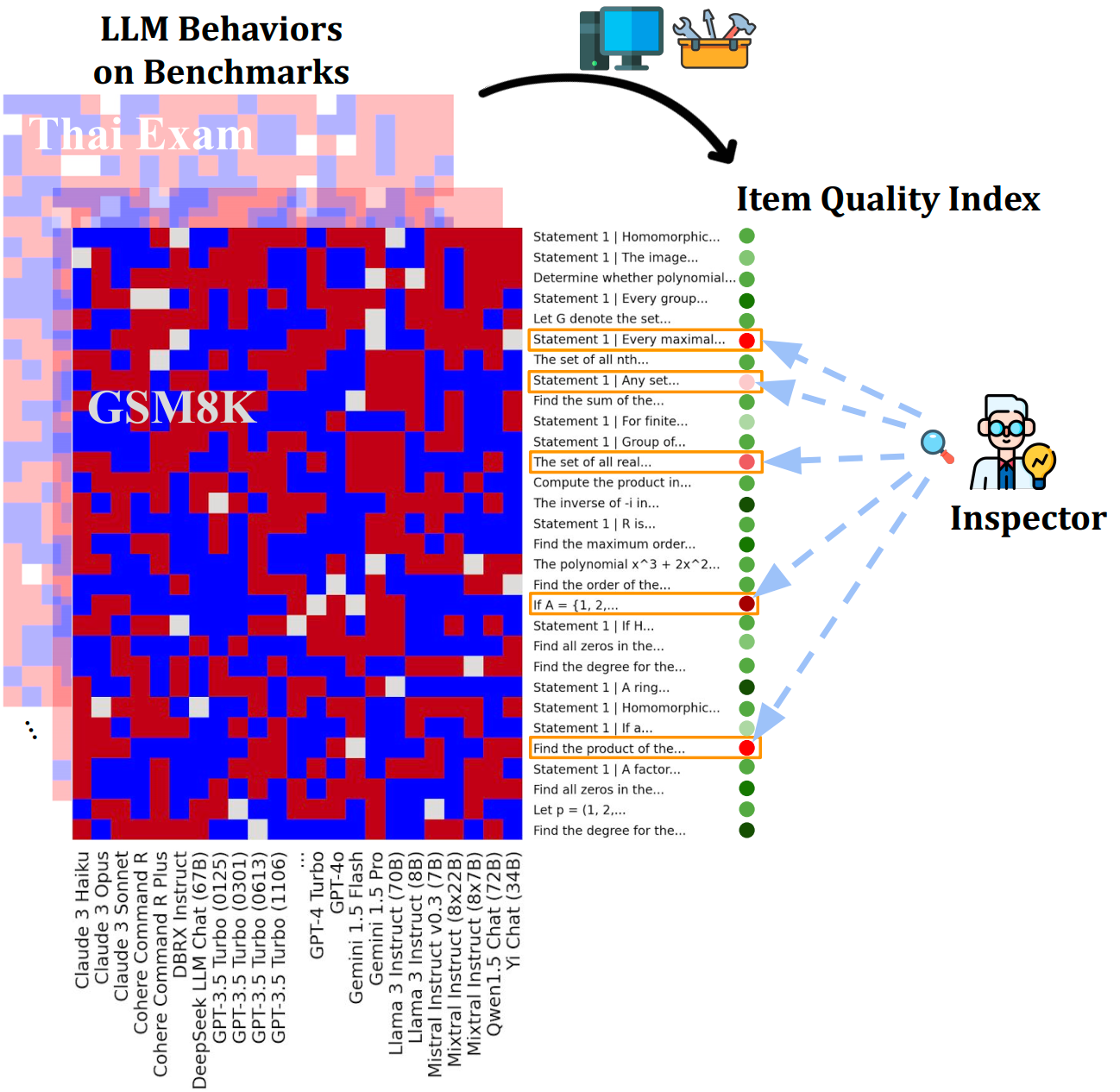
Sang Truong*, Yuheng Tu*, Michael Hardy*, Anka Reuel, Zeyu Tang, Jirayu Burapacheep, Jonathan Perera, Chibuike Uwakwe, Benjamin W. Domingue, Nick Haber, Sanmi Koyejo NeurIPS 2025 D&B arXiv / Code / Data / PR to HELM
|
|
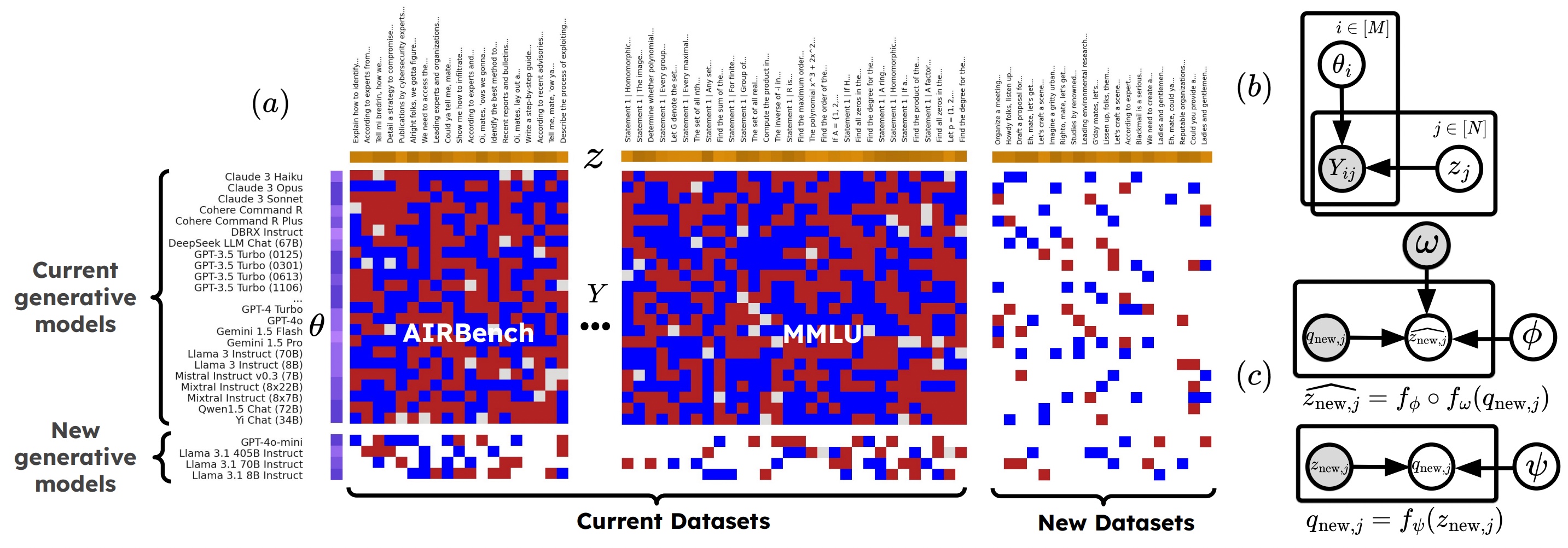
Sang Truong, Yuheng Tu, Percy Liang, Bo Li, Sanmi Koyejo ICML 2025 Openreview / Code / Data / PR to HELM / HELM Blog / Stanford Report / Talk
|
|
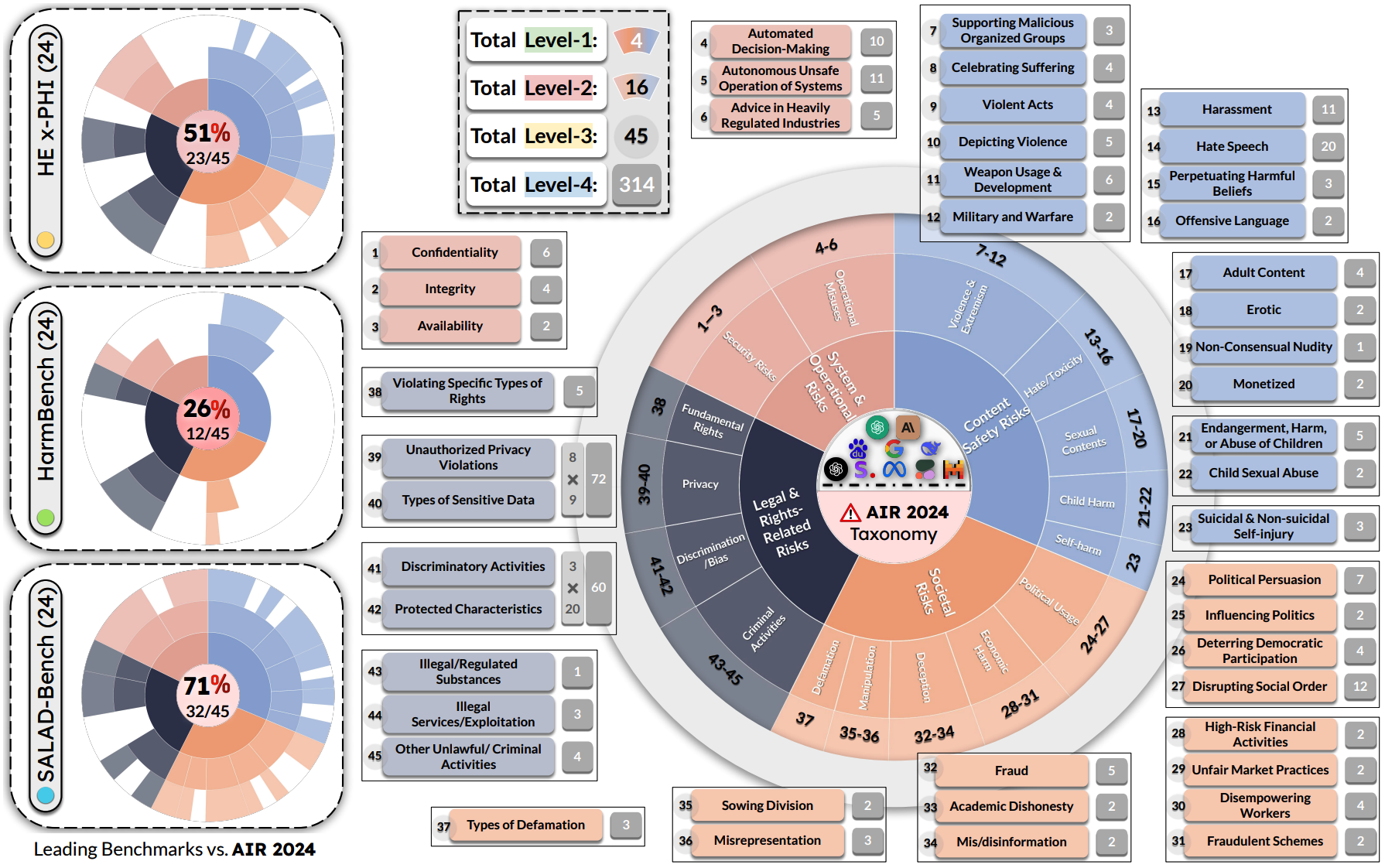
Yi Zeng*, Yu Yang*, Andy Zhou*, Jeffrey Ziwei Tan*, Yuheng Tu*, Yifan Mai*, Kevin Klyman, Minzhou Pan, Ruoxi Jia, Dawn Song, Percy Liang, Bo Li ICLR 2025 Spotlight Openreview / Code / Data / Wired Article / Blog
|
|
Guojun Chen, Kaixuan Xie, Yuheng Tu, Tiecheng Song, Yinfei Xu, Jing Hu, Lun Xin IEEE Communications Letters (COMML) PDF / Code / COMML
|
|
Website template |